Data Frames
Last updated on 2022-12-06 | Edit this page
Overview
Questions
- How to use dataframes in Python?
Objectives
- Import data set as dataframe
- Inspect data frame and access data
- Produce an overview of data features
- Create data plots using matplotlib
Video Tutorials
Introduction
This is our first lesson on learning and understanding dataframes in Python.
Challenge: The diabetes data set
Here is a screenshot of the so-called diabetes data set. It is taken from this webpage and it is one of the example data sets used to illustrate machine learning functionality in scikit-learn (Part III and Part IV of the course).

This figure captures only the top part of the data. On the webpage you need to scroll down considerably to view the whole content. Thus, to get an overview of the dataset is the first main task in Data Science.
The lesson
- introduces code to read and inspect the data
- works with a specific data frame and extracts some techniques to get an overview
- discusses the concept ‘distribution’ as a way of summarising data in a single figure
To get to know a dataset you need to
- access the data
- check the content
- produce a summary of basic properties
In this lesson we will only look at univariate features where each data column is studied independently of the others. Further properties and bivariate features will be the topic of the next lesson.
Work Through Example
Reading data into a Pandas DataFrame
The small practice data file for this section is called ‘everleys_data.csv’ and can be downloaded using the link given above in “Materials for this Lesson”. To start, please create a subfolder called ‘data’ in the current directory and put the data file in it. It can now be accessed using the relative path data/everleys_data.csv or data\everleys_data.csv, respectively.
The file everleys_data.csv contains blood concentrations of calcium and sodium ions from 17 patients with Everley’s syndrome. The data are taken from a BMJ statistics tutorial. The data are stored as comma-separated values (csv), two values for each patient.
To get to know a dataset, we will use the Pandas package and the Matplotlib plotting. The Pandas package for data science is included in the Anaconda distribution of Python. Check this link for installation instructions to get started.
If you are not using the Anaconda distribution, pease refer to these guidelines.
To use the functions contained in Pandas they need to be imported. Our dataset is in ‘.csv’ format, and we therefore need to read it from a csv file. For this, we import the function read_csv. This will create a Pandas dataframe.
PYTHON
import sys
print(sys.version)OUTPUT
3.10.8 (main, Oct 18 2022, 06:43:21) [GCC 9.4.0]PYTHON
from pandas import read_csvERROR
Error in py_call_impl(callable, dots$args, dots$keywords): ModuleNotFoundError: No module named 'pandas'Executing this code does not lead to any output on the screen. However, the function is now ready to be used. To use it, we type its name and provide the required arguments. The following code should import the Everley’s data into your JupyterLab notebook (or other Python environment):
PYTHON
# for Mac OSX and Linux
# (please go to the next cell if using Windows)
df = read_csv("data/everleys_data.csv") ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'read_csv' is not definedPYTHON
# please uncomment for Windows
# (please go to previous cell if using Mac OSX or Linux)
# df = read_csv("data\everleys_data.csv") This code uses the read_csv function from Pandas to read data from a data file, in this case a file with extension ‘.csv’. Note that the location of the data file is specified within quotes by the relative path to the subfolder ‘data’ followed by the file name. Use the JupyterLab file browser to check that subfolder exists and has the file in it.

After execution of the code, the data are contained in a variable called df. This is a structure referred to as a Pandas DataFrame.
A Pandas dataframe is a 2-dimensional labeled data structure with columns of potentially different types. You can think of it as a spreadsheet.
To see the contents of df, simply use:
PYTHON
dfERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not defined(Compare with the result of print(df) which displays the contents in a different format.)
The output shows in the first column an index, integers from 0 to 17; and the calcium and sodium concentrations in columns 2 and 3, respectively. The default indexing starts from zero (Python is a ‘zero-based’ programming language).
In a dataframe, the first column is referred to as Indices, the first row is referred to as Labels. Note that the row with the labels is excluded from the row count. Similarly, the row with the indices is excluded from the column count.
For large data sets, the function head is a convenient way to get a feel of the dataset.
PYTHON
df.head()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedWithout any input argument, this displays the first five data lines of the dataframe. You can specify alter the number of rows displayed by including a single integer as argument, e.g. head(10).
If you feel there are too many decimal places in the default view, you can restrict their number by using the round function:
PYTHON
df.head().round(2)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedWhile we can see how many rows there are in a dataframe when we display the whole data frame and look at the last index, there is a convenient way to obtain the number directly:
PYTHON
no_rows = len(df)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedPYTHON
print('Data frame has', no_rows, 'rows')ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'no_rows' is not definedYou could see above, that the columns of the dataframe have labels. To see all labels:
PYTHON
column_labels = df.columnsERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedPYTHON
print(column_labels)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'column_labels' is not definedNow we can count the labels to obtain the number of columns:
PYTHON
no_columns = len(column_labels)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'column_labels' is not definedPYTHON
print('Data frame has', no_columns, 'columns')ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'no_columns' is not definedAnd if you want to have both the number of the rows and the columns together, use shape. Shape returns a tuple of two numbers, first the number of rows, then the number of columns.
PYTHON
df_shape = df.shapeERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedPYTHON
print('Data frame has', df_shape[0], 'rows and',df_shape[1], 'columns')ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df_shape' is not definedNotice that shape (like columns) is not followed by round parenthesis. It is not a function that can take arguments. Technically, shape is a ‘property’ of the dataframe.
To find out what data type is contained in each of the columns, us dtypes, another ‘property’:
PYTHON
df.dtypesERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedIn this case, both columns contain floating point (decimal) numbers.
DIY1: Read data into a dataframe
Download the data file ‘loan_data.csv’ using the link given above in “Materials for this Lesson”. It contains data that can be used for the assessment of loan applications. Read the data into a DataFrame. It is best to assign it a name other than ‘df’ (to avoid overwriting the Evereley data set).
Display the first ten rows of the Loan data set to see its contents. It is taken from a tutorial on Data Handling in Python which you might find useful for further practice.
From this exercise we can see that a dataframe can contain different types of data: real numbers (e.g. LoanAmount), integers (ApplicantIncome), categorical data (Gender), and strings (Loan_ID).
PYTHON
from pandas import read_csv
# dataframe from .csv fileERROR
Error in py_call_impl(callable, dots$args, dots$keywords): ModuleNotFoundError: No module named 'pandas'PYTHON
df_loan = read_csv("data/loan_data.csv")
# display contentsERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'read_csv' is not definedPYTHON
df_loan.head(10)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df_loan' is not definedAccessing data in a DataFrame
If a datafile is large and you only want to check the format of data in a specific column, you can limit the display to that column. To access data contained in a specific column of a dataframe, we can use a similar convention as in a Python dictionary, treating the column names as ‘keys’. E.g. to show all rows in column ‘Calcium’, use:
PYTHON
df['calcium']ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedTo access individual rows of a column we use two pairs of square brackets:
PYTHON
df['calcium'][0:3]ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedHere all rules for slicing can be applied. As for lists and tuples, the indexing of rows is semi-inclusive, lower boundary included, upper boundary excluded. Note that the first pair of square brackets refers to a column and the second pair refers to the rows. This is different from e.g. accessing items in a nested list.
Accessing items in a Pandas dataframe is analogous to accessing the values in a Python dictionary by referring to its keys.
To access non-contiguous elements, we use an additional pair of square brackets (as if for a list within a list):
PYTHON
df['calcium'][[1, 3, 7]]ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedAnother possibility to index and slice a dataframe is the use of the ‘index location’ or iloc property. It refers first to rows and then to columns by index, all within a single pair of brackets. For example, to get all rows : of the first column (index 0), you use:
PYTHON
df.iloc[:, 0]ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedTo display only the first three calcium concentrations, you use slicing, remembering that the upper bound is excluded):
PYTHON
df.iloc[0:3, 0]ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedTo access non-consecutive values, we can use a pair of square brackets within the pair of square brackets:
PYTHON
df.iloc[[2, 4, 7], 0]ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedSimilarly, we can access the values from multiple columns:
PYTHON
df.iloc[[2, 4, 7], :]ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedTo pick only the even rows from the two columns, check this colon notation:
PYTHON
df.iloc[:18:2, :]ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedThe number after the second colon indicates the stepsize.
DIY2: Select data from dataframe
Display the calcium and sodium concentrations of all patients except the first. Check the model solution at the bottom for options.
PYTHON
df[['calcium', 'sodium']][1:]ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedMixing the ways to access specific data in a dataframe can be confusing and needs practice.
Search for missing values
Some tables contain missing entries. You can check a dataframe for such missing entries. If no missing entry is found, the function isnull will return False.
PYTHON
df.isnull().any()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedThis shows that there are no missing entries in our dataframe.
DIY3: Find NaN in dataframe
In the Loan data set, check the entry ‘Self-employed’ for ID LP001059. It shows how a missing value is represented as ‘NaN’ (not a number).
Verify that the output of isnull in this case is True
PYTHON
df_loan['Self_Employed'][8]ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df_loan' is not definedPYTHON
df_loan['Self_Employed'][8:9].isnull()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df_loan' is not definedBasic data features
Summary Statistics
To get a summary of basic data features use the function describe:
PYTHON
description = df.describe()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedPYTHON
descriptionERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'description' is not definedThe describe function produces a new dataframe (here called ‘descrition’) that contains the number of samples, the mean, the standard deviation, minimum, 25th, 50th, 75th percentile, and the maximum value for each column of the data. Note that the indices of the rows have now been replaced by strings. To access rows, it is possible to refer to those names using the loc property. E.g. to access the mean of the calcium concentrations from the description, each of the following is valid:
PYTHON
# Option 1
description.loc['mean']['calcium']
# Option 2ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'description' is not definedPYTHON
description.loc['mean'][0]
# Option 3ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'description' is not definedPYTHON
description['calcium']['mean']
# Option 4ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'description' is not definedPYTHON
description['calcium'][1]ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'description' is not definedDIY4: Practice
Use your own .csv data set to practice. (If you don’t have a data set at hand, any excel table can be exported as .csv.) Read it into a dataframe, check its header, access indivdual values or sets of values. Create a statistics using describe and check for missing values using .isnull.
[ad libitum]
Iterating through the columns
Now we know how to access all data in a dataframe and how to get a summary statistics over each column.
Here is code to iterate through the columns and access the first two concentrations:
PYTHON
for col in df:
print(df[col][0:2])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedAs a slightly more complex example, we access the median (‘50%’) of each column in the description and add it to a list:
PYTHON
conc_medians = list()
for col in df:
conc_medians.append(df[col].describe()['50%'])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedPYTHON
print('The columns are: ', list(df.columns))ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedPYTHON
print('The medians are: ', conc_medians)OUTPUT
The medians are: []This approach is useful for data frames with a large number of columns. For instance, it is possible to then create a boxplot or histogram for the means, medians etc. of the dataframe and thus to get an overview of all (comparable) columns.
Selecting a subset based on a template
An analysis of a data set may need to be done on part of the data. This can often be formulated by using a logical condition which specifies the required subset.
For this we will assume that some of the data are labelled ‘0’ and some are labelled ‘1’. Let us therefore see how to add a new column to our Evereleys data frame which contains the (in this case arbitrary) labels.
First we randomly create as many labels as we have rows in the data frame. We can use the randint function which we import from ‘numpy.random’. randint in its simple form takes two arguments. First the upper bound of the integer needed, where by default it starts from zero. As Python is exclusive on the upper bound, providing ‘2’ will thus yield either ‘0’ or ‘1’ only.
PYTHON
from numpy.random import randintERROR
Error in py_call_impl(callable, dots$args, dots$keywords): ModuleNotFoundError: No module named 'numpy'PYTHON
no_rows = len(df)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedPYTHON
randomLabel = randint(2, size=no_rows)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'randint' is not definedPYTHON
print('Number of rows: ', no_rows)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'no_rows' is not definedPYTHON
print('Number of Labels:', len(randomLabel))ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'randomLabel' is not definedPYTHON
print('Labels: ', randomLabel)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'randomLabel' is not definedNote how we obtain the number of rows (18) using len and do not put it directly into the code.
Now we create a new data column in our df dataframe which contains the labels. To create a new column, you can simply refer to a column name that does not yet exist and assign values to it. Let us call it ‘gender’, assuming that ‘0’ represents male and ‘1’ represents female.
As gender specification can include more than two labels, try to create a column with more than two randomly assigned labels e.g. (0, 1, 2).
PYTHON
df['gender'] = randomLabelERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'randomLabel' is not definedPYTHON
df.head()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedNow we can use the information contained in ‘gender’ to filter the data by gender. To achieve this, we use a conditional statement. Let us check which of the rows are labelled as ‘1’:
PYTHON
df['gender'] == 1ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedIf we assign the result of the conditional statement (Boolean True or False) to a variable, then this variable can act as a template to filter the data. If we call the data frame with that variable, we will only get the rows where the condition was found to be True:
PYTHON
df_female = df['gender'] == 1ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedPYTHON
df[df_female]ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedUsing the Boolean, we only pick the rows that are labelled ‘1’ and thus get a subset of the data according to the label.
DIY5: Using a template
Modify the code to calculate the number of samples labelled 0 and check the number of rows of that subset.
PYTHON
from numpy.random import randintERROR
Error in py_call_impl(callable, dots$args, dots$keywords): ModuleNotFoundError: No module named 'numpy'PYTHON
no_rows = len(df)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedPYTHON
randomLabel = randint(2, size=no_rows)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'randint' is not definedPYTHON
df['gender'] = randomLabelERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'randomLabel' is not definedPYTHON
df_male = df['gender'] == 0ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedPYTHON
no_males = len(df[df_male])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df' is not definedPYTHON
print(no_males, 'samples are labelled "male".')ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'no_males' is not definedVisualisation of data
It is easy to see from the numbers that the concentrations of sodium are much higher than that of calcium. However, to also compare the medians, percentiles and the spread of the data it is better to use visualisation.
The simplest way of visualisation is to use Pandas functionality which offers direct ways of plotting. Here is an example where a boxplot is created for each column:
PYTHON
import matplotlib.pyplot as pltERROR
Error in py_call_impl(callable, dots$args, dots$keywords): ModuleNotFoundError: No module named 'matplotlib'PYTHON
df = read_csv("data/everleys_data.csv") ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'read_csv' is not definedPYTHON
plt.boxplot(df)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'plt' is not definedPYTHON
plt.show()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'plt' is not definedBy default, boxplots are shown for all columns if no further argument is given to the function (empty round parenthesis). As the calcium plot is rather squeezed we may wish to see it individually. This can be done by specifying the calcium column as an argument:
PYTHON
# Boxplot of calcium results
# df.boxplot(column='calcium');
plt.boxplot(df['calcium'])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'plt' is not definedPYTHON
plt.show()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'plt' is not definedPlots using Matplotlib
Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python.
The above is an easy way to create boxplots directly on the dataframe. It is based on the library Matplotlib and specifically uses the pyplot library. For simplicity, the code is put in a convenient Pandas function.
However, we are going to use Matplotlib extensively later on in the course, and we therefore now introduce the direct, generic way of using it.
For this, we import the function subplots from the pyplot library:
PYTHON
from matplotlib.pyplot import subplotsERROR
Error in py_call_impl(callable, dots$args, dots$keywords): ModuleNotFoundError: No module named 'matplotlib'The way to use subplots is to first set up a figure environment (below it is called ‘fig’) and an empty coordinate system (below called ‘ax’). The plot is then done using one of the many methods available in Matplotlib. We apply it to the coordinate system ‘ax’.
As an example, let us create a boxplot of the calcium variable. As an argument of the function we need to specify the data. We can use the values of the ‘calcium’ concentrations from the column with that name:
PYTHON
fig, ax = subplots()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'subplots' is not definedPYTHON
ax.boxplot(df['calcium'])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax.set_title('Boxplot of Everley\'s Calcium');ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not defined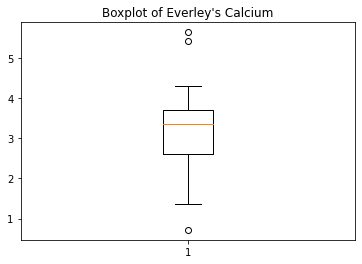
Note how following the actual plot we define the title of the plot by referring to the same coordinate system ax.
The value of subplots becomes apparent when we try to create more than one plot in a single figure.
Here is an example to create two boxplots next to each other. The keyword arguments to use is ‘ncols’ which is the number of figures per row. ‘ncols=2’ indicates that you want to have two plots next to each other.
PYTHON
fig, ax = subplots(ncols=2)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'subplots' is not definedPYTHON
ax[0].boxplot(df['calcium'])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[0].set_title('Calcium')ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[1].boxplot(df['sodium'])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[1].set_title('Sodium');ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not defined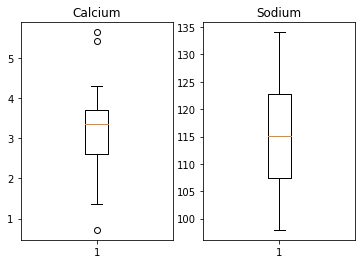
Note that you now have to refer to each of the subplots by indexing the coordinate system ‘ax’. | This figure gives a good overview of the Everley’s data.
If you prefer to have the boxplots of both columns in a single figure, that can also be done:
PYTHON
fig, ax = subplots(ncols=1, nrows=1)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'subplots' is not definedPYTHON
ax.boxplot([df['calcium'], df['sodium']], positions=[1, 2])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax.set_title('Boxplot of Calcium (left) and Sodium (right)')ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not defined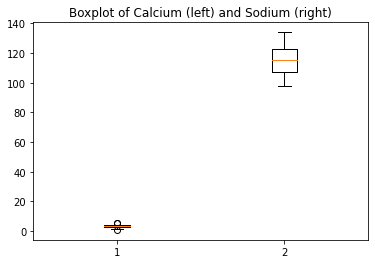
DIY6: Boxplot from Loan data
Plot the boxplots of the ‘ApplicantIncome’ and the ‘CoapplicantIncome’ in the Loan data using the above code.
PYTHON
fig, ax = subplots(ncols=1, nrows=1)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'subplots' is not definedPYTHON
ax.boxplot([df_loan['ApplicantIncome'], df_loan['CoapplicantIncome']], positions=[1, 2])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax.set_title('Applicant Income (left) & Co-Applicant Income (right)');ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not defined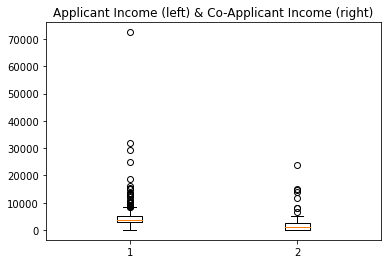
Histogram
Another good overview is the histogram: Containers or ‘bins’ are created over the range of values found within a column and the count of the values for each bin is plotted on the vertical axis.
PYTHON
fig, ax = subplots(ncols=2, nrows=1)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'subplots' is not definedPYTHON
ax[0].hist(df['calcium'])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[0].set(xlabel='Calcium', ylabel='Count');ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[1].hist(df['sodium'])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[1].set(xlabel='Sodium', ylabel='Count');ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
fig.suptitle('Histograms of Everley concentrations', fontsize=15);ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'fig' is not defined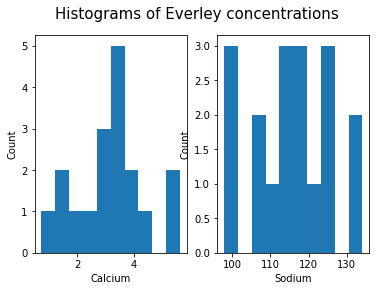
This also shows how to add labels to the axes and a title to the overall figure.
This uses the default value for the generation of the bins. It is set to 10 bins over the range of which values are found. The number of bins in the histogram can be changed using the keyword argument ‘bins’:
PYTHON
fig, ax = subplots(ncols=2, nrows=1)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'subplots' is not definedPYTHON
ax[0].hist(df['calcium'], bins=5)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[0].set(xlabel='Calcium, 5 bins', ylabel='Count');ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[1].hist(df['calcium'], bins=15)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[1].set(xlabel='Calcium, 15 bins', ylabel='Count');ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
fig.suptitle('Histograms with Different Binnings', fontsize=16);ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'fig' is not defined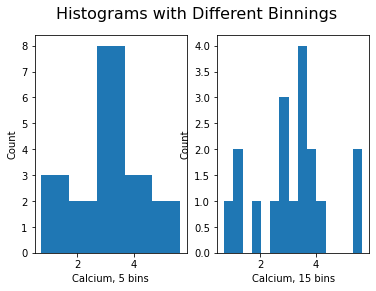
Note how the y-label of the right figure is not placed well. To correct for the placement of the labels and the title, you can use tight_layout on the figure:
PYTHON
fig, ax = subplots(ncols=2, nrows=1)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'subplots' is not definedPYTHON
ax[0].hist(df['calcium'], bins=5)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[0].set(xlabel='Calcium, 5 bins', ylabel='Count');ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[1].hist(df['calcium'], bins=15)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax[1].set(xlabel='Calcium, 15 bins', ylabel='Count');ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
fig.suptitle('Histograms with Different Binnings', fontsize=16);ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'fig' is not definedPYTHON
fig.tight_layout()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'fig' is not defined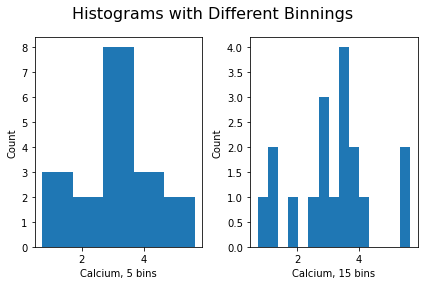
DIY7: Create the histogram of a column
Take the loan data and display the histogram of the loan amount that people asked for. (Loan amounts are divided by 1000, i.e. in k£ on the horizontal axis). Use e.g. 20 bins.
PYTHON
# Histogram of loan amounts in k£
fig, ax = subplots()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'subplots' is not definedPYTHON
ax.hist(df_loan['LoanAmount'], bins=20)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax.set(xlabel='Loan amount', ylabel='Count');ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not definedPYTHON
ax.set_title('Histograms of Loan Amounts', fontsize=16);ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not defined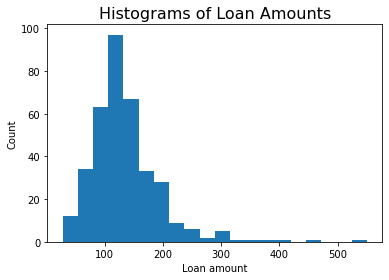
Handling the Diabetes Data Set
We now return to the data set that started our enquiry into the handling of data in a dataframe.
We will now:
- Import the diabetes data from ‘sklearn’
- Check the shape of the dataframe and search for NANs
- Get a summary plot of one of its statistical quantities (e.g. mean) for all columns
First we import the data set and check its head. Wait until the numbers show below the code, it might take a while.
PYTHON
from sklearn import datasetsERROR
Error in py_call_impl(callable, dots$args, dots$keywords): ModuleNotFoundError: No module named 'sklearn'PYTHON
diabetes = datasets.load_diabetes()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'datasets' is not definedPYTHON
X = diabetes.dataERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'diabetes' is not definedPYTHON
from pandas import DataFrameERROR
Error in py_call_impl(callable, dots$args, dots$keywords): ModuleNotFoundError: No module named 'pandas'PYTHON
df_diabetes = DataFrame(data=X)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'DataFrame' is not definedPYTHON
df_diabetes.head()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df_diabetes' is not definedIf you don’t see all columns, use the cursor to scroll to the right.
Now let’s check the number of columns and rows.
PYTHON
no_rows = len(df_diabetes)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df_diabetes' is not definedPYTHON
no_cols = len(df_diabetes.columns)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df_diabetes' is not definedPYTHON
print('Rows:', no_rows, 'Columns:', no_cols)ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'no_rows' is not definedThere are 442 rows organised in 10 columns.
To get an overview, let us extract the mean of each column using ‘describe’ and plot all means as a bar chart. The Matplotlib function to plot a bar chart is bar:
PYTHON
conc_means = list()
for col in df_diabetes:
conc_means.append(df_diabetes[col].describe()['mean'])ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df_diabetes' is not definedPYTHON
print('The columns are: ', list(df_diabetes.columns))ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'df_diabetes' is not definedPYTHON
print('The medians are: ', conc_means, 2)OUTPUT
The medians are: [] 2PYTHON
fig, ax = subplots()ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'subplots' is not definedPYTHON
bins = range(10)
ax.bar(bins, conc_means);ERROR
Error in py_call_impl(callable, dots$args, dots$keywords): NameError: name 'ax' is not defined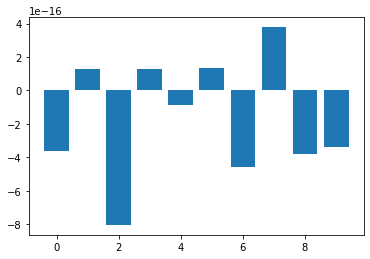
The bars in this plot go up and down. Note, however, that the vertical axis has values ranging from -10^(-15) to +10^(-15). This means that for all practical purposes all means are zero. This is not a coincidence. The original values have been normalised to zero mean for the purpose of applying some machine learning algorithm to them.
In this example, we see how important it is to check the data before working with them.
Assignment: The cervical cancer data set
Download the cervical cancer data set provided, import it using read_csv.
- How many rows and columns are there?
- How many columns contain floating point numbers (float64)?
- How many of the subjects are smokers?
- Calculate the percentage of smokers
- Plot the age distribution (with e.g. 50 bins)
- Get the mean and standard distribution of age of first sexual intercourse
Keypoints
- learned importing data set as dataframe
- learned inspecting data frame and accessing data
- Producing an overview of data features
- Creating data plots using matplotlib
Download the pdf
This section’s pdf can be accessed at:Download pdf
Download jupyter notebook
This section’s material in jupyter notebook can be accessed at:Download notebook (ipynb)